Tools andExamples
Various tools and platforms facilitate data orchestration, offering features such as data integration, transformation, and workflow automation. Here are some tools and examples of data orchestration:
Azure Data Factory
Azure Data Factory is a comprehensive data integration and orchestration service with a range of key features and capabilities. It allows you to integrate data from various sources, including on-premises systems, cloud platforms, relational databases, Big Data sources, and SaaS applications. Data workflows can be defined and executed using visual tools or code-based configurations, with pipelines consisting of activities for data ingestion, transformation, and movement. The service offers built-in data transformation capabilities through Mapping Data Flow, providing a code-free approach for designing and executing
data transformations. Data movement between different data stores is efficient and supports both batch and real-time scenarios. Azure Data Factory also includes data governance and security features, such as encryption, RBAC, and integration with Azure Active Directory. It seamlessly integrates with other Azure services, enabling you to leverage their capabilities within your data integration pipelines. Monitoring and management features allow for tracking pipeline execution, monitoring activity performance, and troubleshooting, with integration options for advanced monitoring and alerting. The service is scalable, cost-efficient, and provides auto-scaling capabilities to optimize resource allocation. Azure Data Factory empowers organizations to build scalable and efficient data pipelines, making it a powerful tool for managing data workflows in the cloud.
Azure Data Factory consists of several important components that contribute to its data integration and orchestration capabilities. These components include linked services, datasets, pipelines, activities, triggers, and integration runtimes (Figure 5-6).
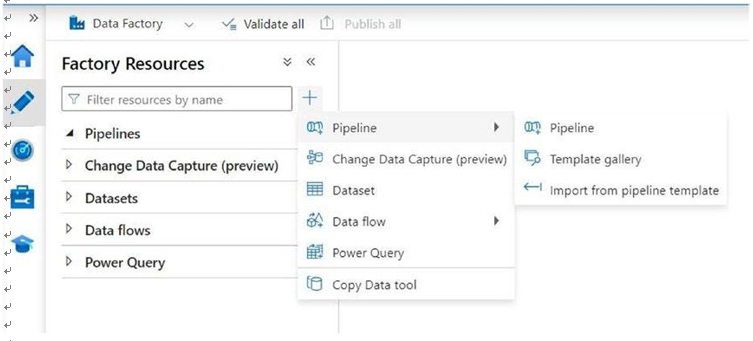
Figure 5-6. Azure Data Factory panel depicting different features
• Linked Services represent connections to various data sources and destinations, such as Azure Storage, Azure SQL Database, and on- premises systems. They are configured to establish connectivity and enable data movement.
• Datasets define the data structures in the source and destination data stores. They specify the format, schema, and location of the data. Datasets serve as the foundation for data integration and transformation operations.
• Pipelines are the core building blocks of Azure Data Factory. They define the workflow and sequence of activities to be executed. Activities can include data ingestion, transformation, movement, or processing tasks. Pipelines are created using a visual designer or JSON code.
• Triggers are used to schedule or initiate the execution of pipelines. Time-based schedules and event-based triggers, such as Azure Blob storage events or Azure Logic Apps, can be configured to start the execution of pipelines at specific intervals or based on specific events.
• Integration runtimes provide the execution environment for data integration tasks. They can be used to run pipelines on Azure infrastructure, self-hosted infrastructure, or as an Azure Data Factory–managed integration runtime.
Azure Data Factory also includes the powerful feature of data flows. Data flows in Azure Data Factory provide a visual, code-free environment for designing and executing complex data transformation logic. They allow users to visually build data transformation workflows using a wide range of data transformation operations, such as data cleansing, filtering, aggregation, joins, and custom transformations. With data flows, users can efficiently transform and cleanse large volumes of data in a scalable and serverless manner. This feature empowers organizations to streamline and automate their data preparation and transformation tasks, ultimately enabling them to derive valuable insights from their data. By integrating data flows into their data pipelines, users can leverage the flexibility and ease of use of this component to achieve comprehensive data integration and transformation within Azure Data Factory.
Working with Azure Data Factory (ADF) involves designing and orchestrating data workflows, ingesting data from various sources, transforming and processing it, and loading it into target destinations. Azure Data Factory is a cloud-based data integration service that allows you to create, schedule, and manage data pipelines.
Here is a step-by-step guide to working with Azure Data Factory:
Set Up Azure Data Factory
• Create an Azure Data Factory instance in the Azure portal.
• Select the appropriate subscription, resource group, and region for your data factory.
• Configure Linked Services to connect to various data sources, like Azure Storage, Azure SQL Database, Azure Data Lake Storage, on- premises systems, or other cloud services.
Define Datasets
Datasets represent the data structures in your data sources and destinations.
• Define the structure and properties of datasets, including file formats, schema, and location.
Create Pipelines
Pipelines define the workflow and activities to be executed in a specific sequence.
• Create pipelines in ADF using a visual designer or by writing JSON code.
• Add activities to the pipeline, such as data ingestion, data transformation, data movement, or data processing activities.
Configure Activities
• Configure each activity in the pipeline according to its purpose.
• For data ingestion, specify the source dataset and linked service.
• For data transformation (i.e., filter, sort, join, merge, etc.), use data transformation tools like ADF Dataflow, Azure Databricks, Azure HDInsight, or Azure Synapse Analytics.
• For data movement, specify the source and destination datasets and linked services.
• For data processing, define the necessary operations or computations to be performed.
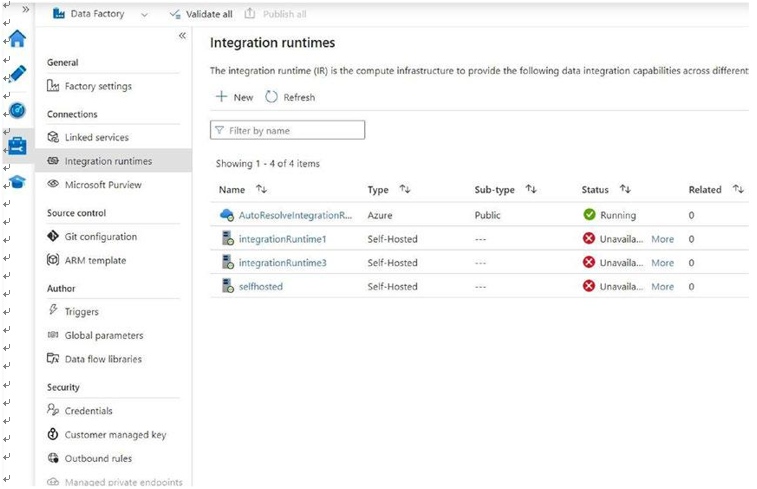
Figure 5-7. Azure integration runtime
Note: “Auto-resolve integration runtime” is always active, which interacts with other Azure sources. Inactive runtimes are self-hosted integration runtimes installed on an on-premises instance.
Schedule and Trigger Pipelines
• Set up a schedule or trigger to execute the pipeline at specific intervals or based on events.
• Use ADF’s built-in triggers, such as time-based schedules or event- based triggers, like Azure Blob storage events or Azure Logic Apps.
Monitor and Troubleshoot
• Monitor the execution of your pipelines using Azure Data Factory monitoring capabilities (Figure 5-8).
• Monitor pipeline runs, track activity statuses, and review diagnostic logs for troubleshooting.
• Utilize ADF’s integration with Azure Monitor and Azure Log Analytics for advanced monitoring and alerting.
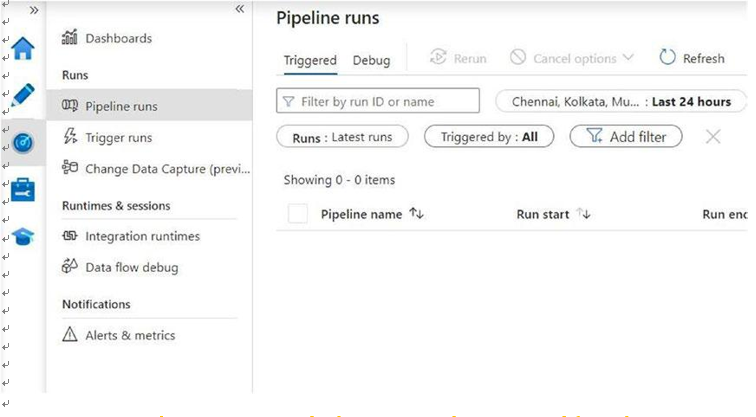
Figure 5-8. Pipeline, triggers, and other runs can be monitored from the section in the screenshot gatherd from a live Azure Data Factory instance
Data Integration and Transformation
• Use ADF’s data integration capabilities to perform data cleansing, filtering, aggregation, joins, or custom transformations, or use Notebook from Databricks or Synapse analytics to transform and shape the data as required.
Azure Data Factory provides a flexible and scalable platform for building and managing data integration workflows. By following these steps, you can design, schedule, monitor, and optimize data pipelines to efficiently integrate, transform, and move data across various sources and destinations within the Azure ecosystem.