Example and Use Case
Delta lakes have gained popularity as a reliable solution for processing delta files in data lakes. Regardless of the technology used, the steps for processing delta tables remain consistent as long as the technology supports delta table processing.
In this particular use case, Azure Data Factory (ADF) is utilized to process delta tables. ADF is chosen as the preferred option due to the scenario where new clients, particularly those with C-suite executives not involved, may be hesitant to adopt technologies like Databricks or Spark. These clients might prefer Microsoft-agnostic solutions, and in such cases Azure Data Factory serves as the best and easiest way to gradually introduce them to the benefits of using delta tables.
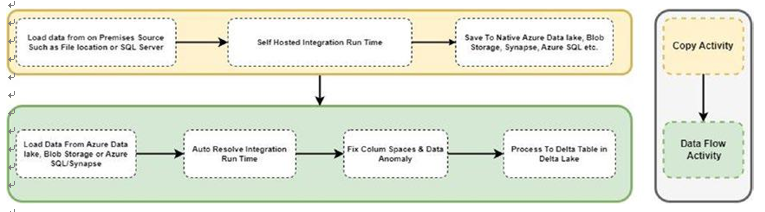
Figure 5-13. Flow for delta table creation using Azure Data Factory
To process files in delta tables using Azure Data Factory, you can follow these steps:
Set Up Azure Data Factory
• Create an Azure Data Factory instance in the Azure portal (Figure 5-14).
• Select the appropriate subscription, resource group, and region for your data factory.
Figure 5-14. Azure Data Factory instance screenshot
Define Source and Sink
• Identify the source where your files are located. It could be Azure Blob storage, Azure Data Lake Storage, or any other supported storage service.
• In Azure Data Factory, you need to define the source dataset, which involves specifying the connection details and file format of the source files. The source dataset can be a SQL server table, and if the table is hosted on-premises, you will need to use a self- hosted integration runtime to access the data. Alternatively, the source dataset can be a CSV file, TSV file, Parquet file, or other supported format.
Create a Pipeline
• Within Azure Data Factory, go to the Authoring section and select “Pipelines.”
• Create a new pipeline and provide a name for it.
• Add a copy activity to the pipeline that represents the file- processing task.
• Configure the activity to use the appropriate source and sink datasets.
• In case the data is being copied from an on-premises data source such as a file or on-premises database, you need to copy data first to a Native Azure source, such as Azure Delta Lake Storage, Azure SQl, Azure Synapse, using a copy activity.
• Load the data as CSV, Azure SQL/Synapse table, or Parquet in the Native Azure data source.
The Figure below, labeled 5-15, illustrates a typical example of loading a Delta table via data flow in Data Factory along with other dataprocessing activities.

Figure 5-15. Azure Data Factory high-level activity for delta table load
Identify the target delta table where you want to load the processed data.
• Define the sink dataset in Azure Data Factory, specifying the connection details and format of the delta table.
Some Constraints and Options
Writing data in delta format is only supported through data flow in Azure Data Factory. Therefore, if the data is located on-premises, you will need to migrate it to Azure native Blob storage, ADLS Gen2, Azure SQL, or Synapse to proceed with delta format utilization.
To work with delta format in Azure Data Factory, you can utilize the self-hosted integration runtime by employing the copy activity. This allows you to save the data in Parquet or CSV format, which can then be further processed in delta format using Data Flow.
Alternatively, you have the option to use Python in Spark or Databricks notebook for data processing. These notebooks can be executed using the Azure Data Factory option to execute notebooks, enabling you to work with delta format seamlessly.
By considering these approaches, you can effectively work with delta format in Azure Data Factory. If the data is on-premises, ensure its migration to compatible storage, employ the self-hosted integration runtime for saving in compatible formats, or leverage Python and Spark capabilities via Databricks notebook execution in Azure Data Factory.